Contrastive Learning for Lane Detection via cross-similarity
Detecting lane markings in road scenes poses a significant challenge due to their intricate nature, which is susceptible to unfavorable conditions. While lane markings have strong shape priors, their visibility is easily compromised by varying lighting conditions, adverse weather, occlusions by other vehicles or pedestrians, road plane changes, and fading of colors over time. The detection process is further complicated by the presence of several lane shapes and natural variations, necessitating large amounts of high-quality and diverse data to train a robust lane detection model capable of handling various real-world scenarios.
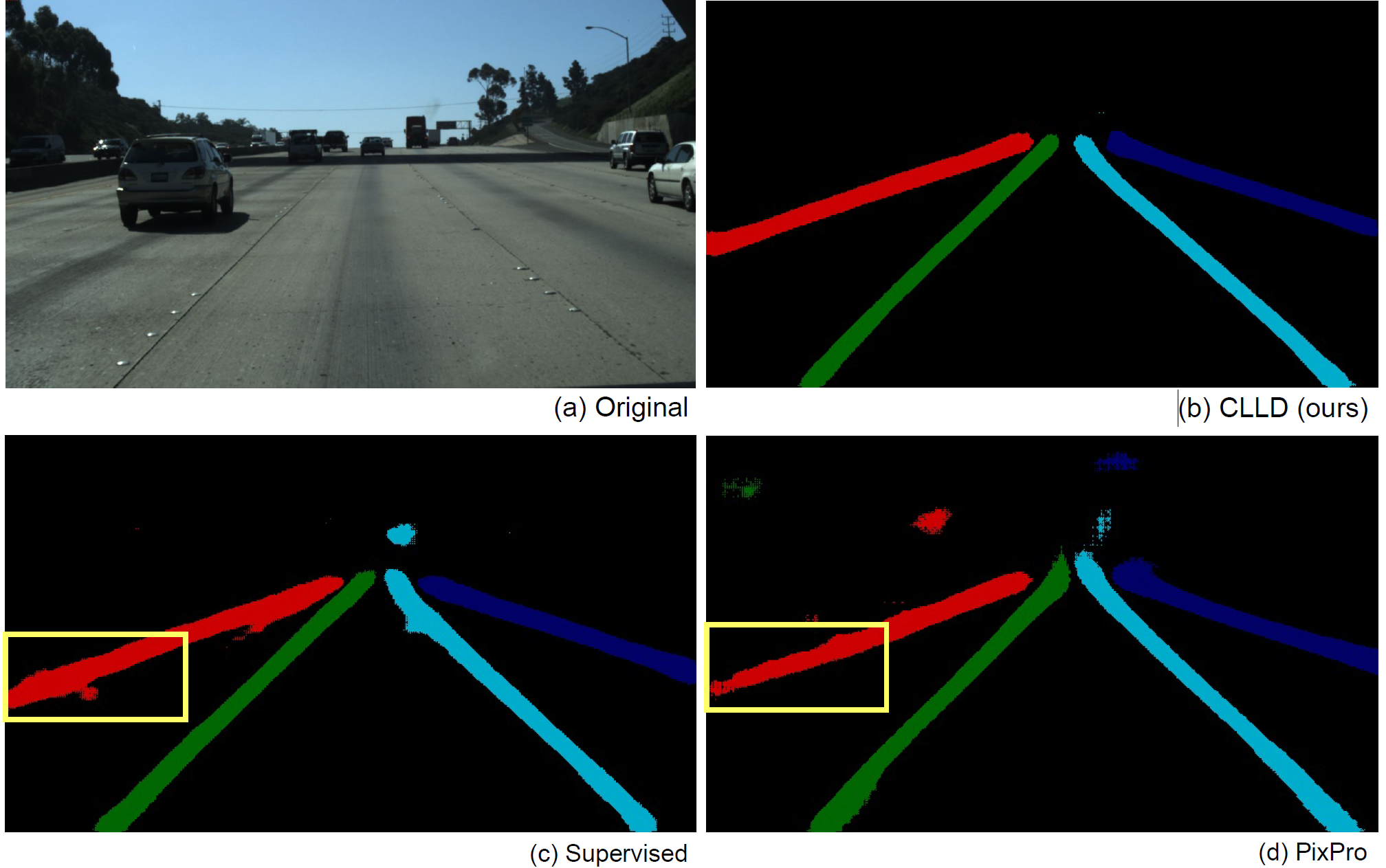
In this paper, we present a novel self-supervised learning method termed Contrastive Learning for Lane Detection via Cross-Similarity (CLLD) to enhance the resilience and effectiveness of lane detection models in real-world scenarios, particularly when the visibility of lane markings are compromised. CLLD introduces a novel contrastive learning (CL)
method that assesses the similarity of local features within the global context of the input image. It uses the surrounding information to predict lane markings. This is achieved by integrating local feature contrastive learning with our newly proposed operation, dubbed cross-similarity.
The local feature CL concentrates on extracting features from small patches, a necessity for accurately localizing lane segments. Meanwhile, cross-similarity captures global features, enabling the detection of obscured lane segments based on their surroundings. We enhance cross-similarity by randomly masking portions of input images in the process of augmentation. Extensive experiments on TuSimple and CuLane benchmark datasets demonstrate that CLLD consistently outperforms state-of-the-art contrastive learning methods, particularly in visibility-impairing conditions like shadows, while it also delivers comparable results under normal conditions. When compared to supervised learning, CLLD still excels in challenging scenarios such as shadows and crowded scenes, which are common in real-world driving.
TrajectoryNAS: A Neural Architecture Search for Trajectory Prediction
Autonomous driving systems are a rapidly evolving technology.
Trajectory prediction is a critical component of autonomous driving systems that enables safe navigation by anticipating the movement of surrounding objects.
Lidar point-cloud data provide a 3D view of solid objects surrounding the ego-vehicle.
Hence, trajectory prediction using Lidar point-cloud data performs better than 2D RGB cameras due to providing the distance between the target object and the ego-vehicle. However, processing point-cloud data is a costly and complicated process, and state-of-the-art 3D trajectory predictions using point-cloud data suffer from slow and erroneous predictions.
State-of-the-art trajectory prediction approaches suffer from handcrafted and inefficient architectures, which can lead to low accuracy and suboptimal inference times. Neural architecture search (NAS) is a method proposed to optimize neural network models by using search algorithms to redesign architectures based on their performance and runtime.
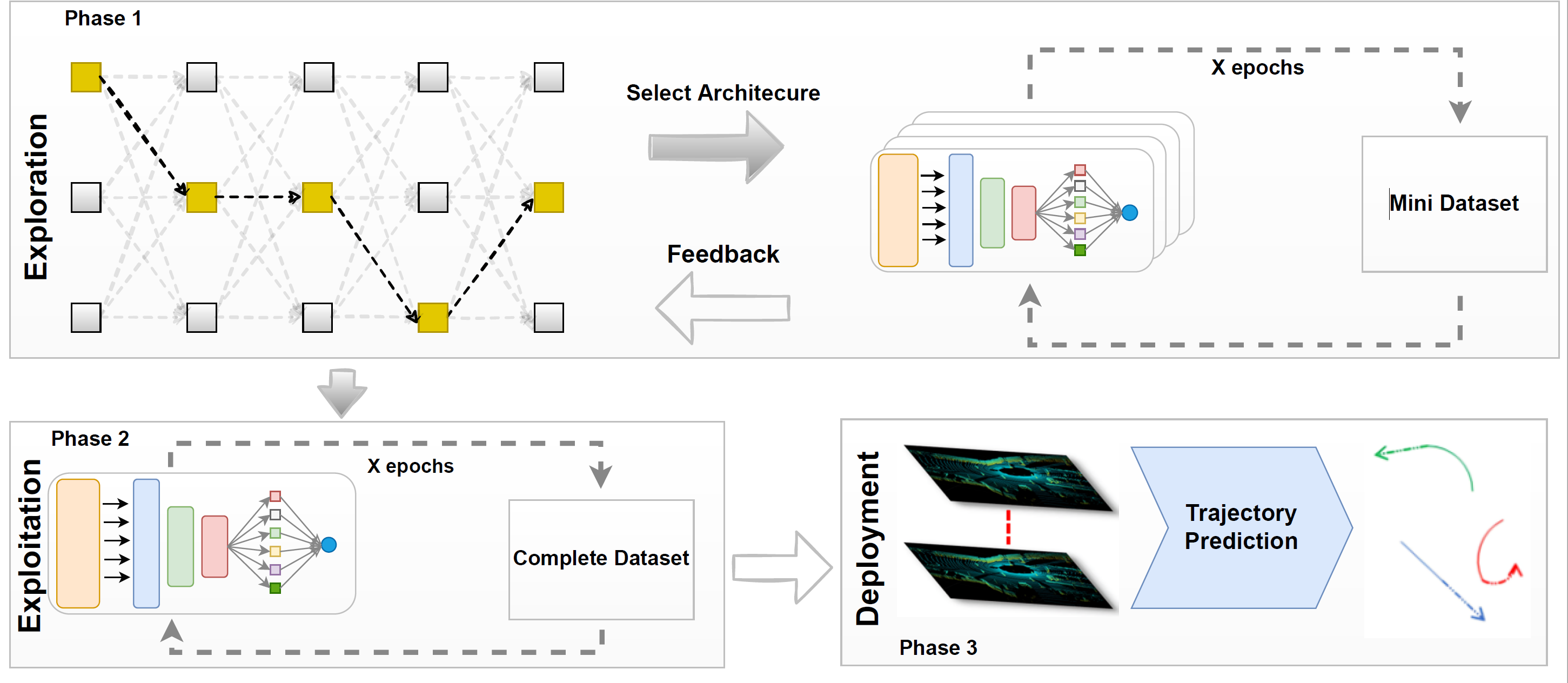
This paper introduces TrajectoryNAS, a novel neural architecture search (NAS) method designed to develop an efficient and more accurate LiDAR-based trajectory prediction model for predicting the trajectories of objects surrounding the ego vehicle.
TrajectoryNAS systematically optimizes the architecture of an end-to-end trajectory prediction algorithm, incorporating all stacked components that are prerequisites for trajectory prediction, including object detection and object tracking, using metaheuristic algorithms.
This approach addresses the neural architecture designs in each component of trajectory prediction, considering accuracy loss and the associated overhead latency. Our method introduces a novel multi-objective energy function that integrates accuracy and efficiency metrics, enabling the creation of a model that significantly outperforms existing approaches.
Through empirical studies, TrajectoryNAS demonstrates its effectiveness in enhancing the performance of autonomous driving systems, marking a significant advancement in the field.
RReLU: Reliable ReLU Toolbox (RReLU) To Enhance Resilience of DNNs
The Reliable ReLU Toolbox (RReLU) is a powerful reliability tool designed to enhance the resiliency of deep neural networks (DNNs) by generating reliable ReLU activation functions. It is Implemented for the popular PyTorch deep learning platform. RReLU allows users to find a clipped ReLU activation function using various methods. This tool is highly versatile for dependability and reliability research, with applications ranging from resiliency analysis of classification networks to training resilient models and improving DNN interpretability.
RReLU includes all state-of-the-art activation restriction methods. These methods offer several advantages: they do not require retraining the entire model, avoid the complexity of fault-aware training, and are non-intrusive, meaning they do not necessitate any changes to an accelerator. RReLU serves as the research code accompanying the paper (ProAct: Progressive Training for Hybrid Clipped Activation Function to Enhance Resilience of DNNs), and it includes implementations of the following algorithms:
- ProAct (the proposed algorithm) (paper and (code).
- FitAct (paper and code).
- FtClipAct (paper and code).
- Ranger (paper and code).
DASS: DIFFERENTIABLE ARCHITECTURE SEARCH FOR SPARSE NEURAL NETWORKS
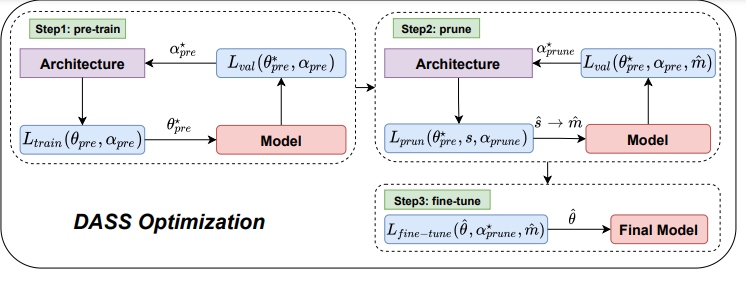
The deployment of Deep Neural Networks (DNNs) on edge devices is hindered by the substantial gap between performance requirements and available processing power. While recent research has made significant strides in developing pruning methods to build a sparse network for reducing the computing overhead of DNNs, there remains considerable accuracy loss, especially at high pruning ratios. We find that the architectures designed for dense networks by differentiable architecture search methods are ineffective when pruning mechanisms are applied to them. The main reason is
that the current method does not support sparse architectures in their search space and uses a search objective that is made for dense networks and does not pay any attention to sparsity.
In this paper, we propose a new method to search for sparsity-friendly neural architectures. We do this by adding two new sparse operations to the search space and modifying the search objective. We propose two novel parametric SparseConv and SparseLinear operations in order to expand the search space to include sparse operations. In particular, these operations make a flexible search space due to using sparse parametric versions of linear and convolution operations. The proposed search objective lets us train the architecture based on the sparsity of the search space operations. Quantitative analyses demonstrate that our search architectures outperform those used in the stateof-the-art sparse networks on the CIFAR-10 and ImageNet datasets. In terms of performance and hardware effectiveness, DASS increases the accuracy of the sparse version of MobileNet-v2 from 73.44% to 81.35% (+7.91% improvement) with 3.87× faster inference time
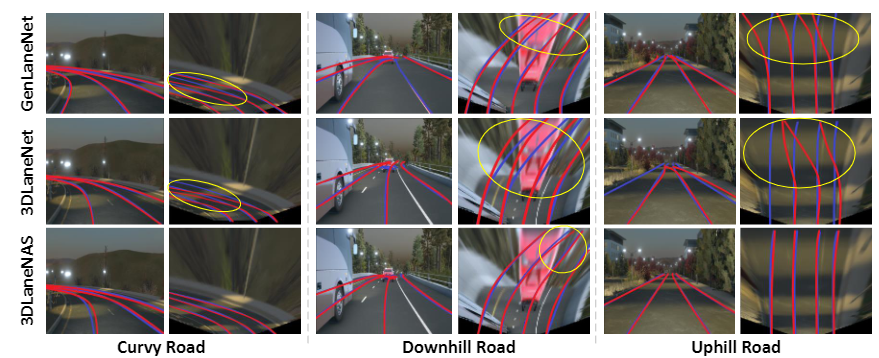
3DLaneNAS: Neural Architecture Search for Accurate and Light-Weight 3D Lane Detection
Lane detection is one of the most fundamental tasks for autonomous driving. It plays a crucial role in the lateral control and the precise localization of autonomous vehicles. Monocular 3D lane detection methods provide state-of-the-art results for estimating the position of lanes in 3D world coordinates using only the information obtained from the front-view camera. Recent advances in Neural Architecture Search (NAS) facilitate automated optimization of various computer vision tasks. NAS can automatically optimize monocular 3D lane detection methods to enhance the extraction and combination of visual features, consequently reducing computation loads and increasing accuracy. This paper proposes 3DLaneNAS, a multi-objective method that enhances the accuracy of monocular 3D lane detection for both short- and long-distance scenarios while at the same time providing a fair amount of hardware acceleration. 3DLaneNAS utilizes a new multi-objective energy function to optimize the architecture of feature extraction and feature fusion modules simultaneously. Moreover, a transfer learning mechanism is used to improve the convergence of the search process. Experimental results reveal that 3DLaneNAS yields a minimum of 5.2 % higher accuracy and 1.33 * lower latency over competing methods on the synthetic-3D-lanes dataset.
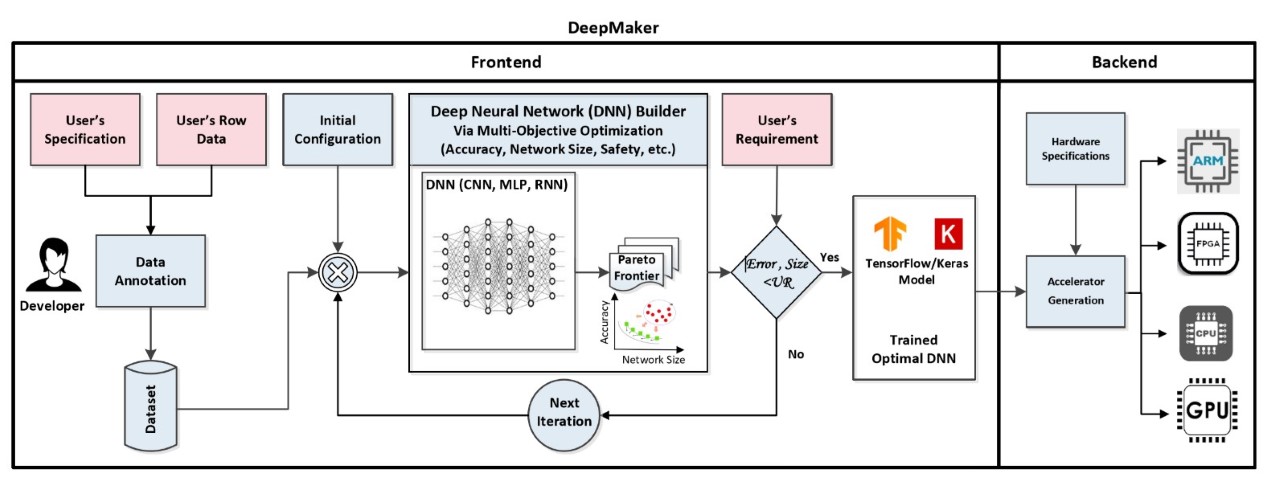
DeepMaker - Deep Learning Accelerator on Programmable Devices
In recent years, deep neural networks (DNNs) has shown excellent performance on many challenging machine learning tasks, such as image classification, speech recognition, and unsupervised learning tasks. The Complex DNNs applications require a great amount of computation, storage, and memory bandwidth to provide a desirable trade-off between accuracy and performance which makes them not suitable to be deployed on resource-limited embedded systems. DeepMaker aims to provide optimized DNN models including Convolutional Neural Network (CNN) and Recurrent Neural Network (RNN) that are customized for deployment on resource-limited embedded hardware platforms. To customize DNN for resource-limited embedded platforms, we have proposed this framework, with the aim of automatic design and optimization of deep neural architectures using multi-objective Neural Architecture Search (NAS). In the DeepMaker project [1][2][3], we have proposed novel architectures that are able to do inference in run-time on embedded hardware, while achieving significant speedup/ performance with negligible accuracy loss. Furthermore, to accelerate the inference of DNN on resource-limited embedded devices, we also consider using quantization techniques as one of the most popular and efficient techniques to reduce the massive amount of computations and as well the memory footprint and access in deep neural networks [4][5][6].
TAS: Ternarized Neural Architecture Search for Resource-Constrained Edge Devices
Deep Neural Networks (DNNs) have successfully been adapted to various computer vision tasks. In general, there is an increasing demand to deploy DNNs onto resource-constrained edge devices due to energy efficiency, privacy, and stable connectivity concerns. However, the enormous computational intensity of DNNs cannot be supported by resource-constrained edge devices leading to the failure of existing processing paradigms in affording modern application requirements. A Ternary Neural Network (TNN), where both weights and activation functions are quantized to ternary tensors, is a variation of network quantization techniques that comes with the benefits of network compression and operation acceleration. However, TNNs still suffer from a substantial accuracy drop issue, hampering them from being widely used in practice. Neural Architecture Search (NAS) is a method which can automatically design high-performance networks. The idea of our proposed framework, dubbed TAS, is to integrate the ternarization mechanism into NAS with the hope of reducing the accuracy gap of TNNs.

DeepHLS V1.0
DeepHLS is a fully automated toolchain for creating a C-level implementation that is synthesizable with HLS Tools. It includes various stages, including Keras to C, Validation, Quantization analysis, and Quantization application. Thanks to its various scalability features, it supports very large deep neural networks such as VGG.

DeepAxe
While the role of Deep Neural Networks (DNNs) in a wide range of safety-critical applications is expanding, emerging DNNs experience massive growth in terms of computation power.
It raises the necessity of improving the reliability of DNN accelerators yet reducing the computational burden on the hardware platforms, i.e., reducing the energy consumption and execution time as well as increasing the efficiency of DNN accelerators.
Therefore, the trade-off between hardware performance, i.e., area, power, and delay, and the reliability of the DNN accelerator implementation becomes critical and requires tools for analysis.
DeepAxe, an extention to DeepHLS, is a framework and tool for design space exploration of FPGA-based implementation of DNNs by considering the trilateral impact of applying functional approximation on accuracy, reliability, and hardware performance.

CoMA: Configurable Many-core Accelerator for Embedded Systems
We have developed the Configurable Many-core Accelerator (CoMA) for (FPGA-based) embedded systems. Its architecture comprises an array of processing and I/O-specialized cores interconnected by NoC. The I/O cores provide the connectivity with other system components through the industry-standard Advanced eXtensible Interface (AXI) bus. In a typical design flow, an application is partitioned and the most compute-demanding tasks are executed on the accelerator. With the proposed approach, the details of task synchronization and I/O access of the accelerator are hidden by an abstraction layer. Task partitioning is left to the designer, thus allowing more flexibility during application development than with automatized partitioning. The high level view of the system leverages the customization of the accelerator on an application basis. This way, CoMA promotes the development of many-core solutions for highly specialized applications.
CGRA: Configurable Many-core Accelerator for Embedded Systems
The increasing speed and performance requirements of multimedia and mobile applications, coupled with the demands for flexibility and low non-recurring engineering costs, have made reconfigurable hardware a very popular implementation platform. We have developed a Coarse Grained Reconfigurable Architectures (CGRA), provide operator level configurable functional blocks, word level data paths, and very area- efficient routing switches. Compared to the fine-grained architectures (like FPGAs), the CGRA not only requires lesser configuration memory and time but also achieves a significant reduction in area and energy consumed per computation, at the cost of a loss in flexibility compared to bit-level operations. Our CGRA has been developed based on the the Dynamically Reconfigurable Resource Array (DRRA) composed of three main components: (i) system controller, (ii) computation layer, and (iii) memory layer. For each hosted application in CGRA, a separate partition can be created in memory and computation layers. The partition is optimal in terms of energy, power, and reliability.
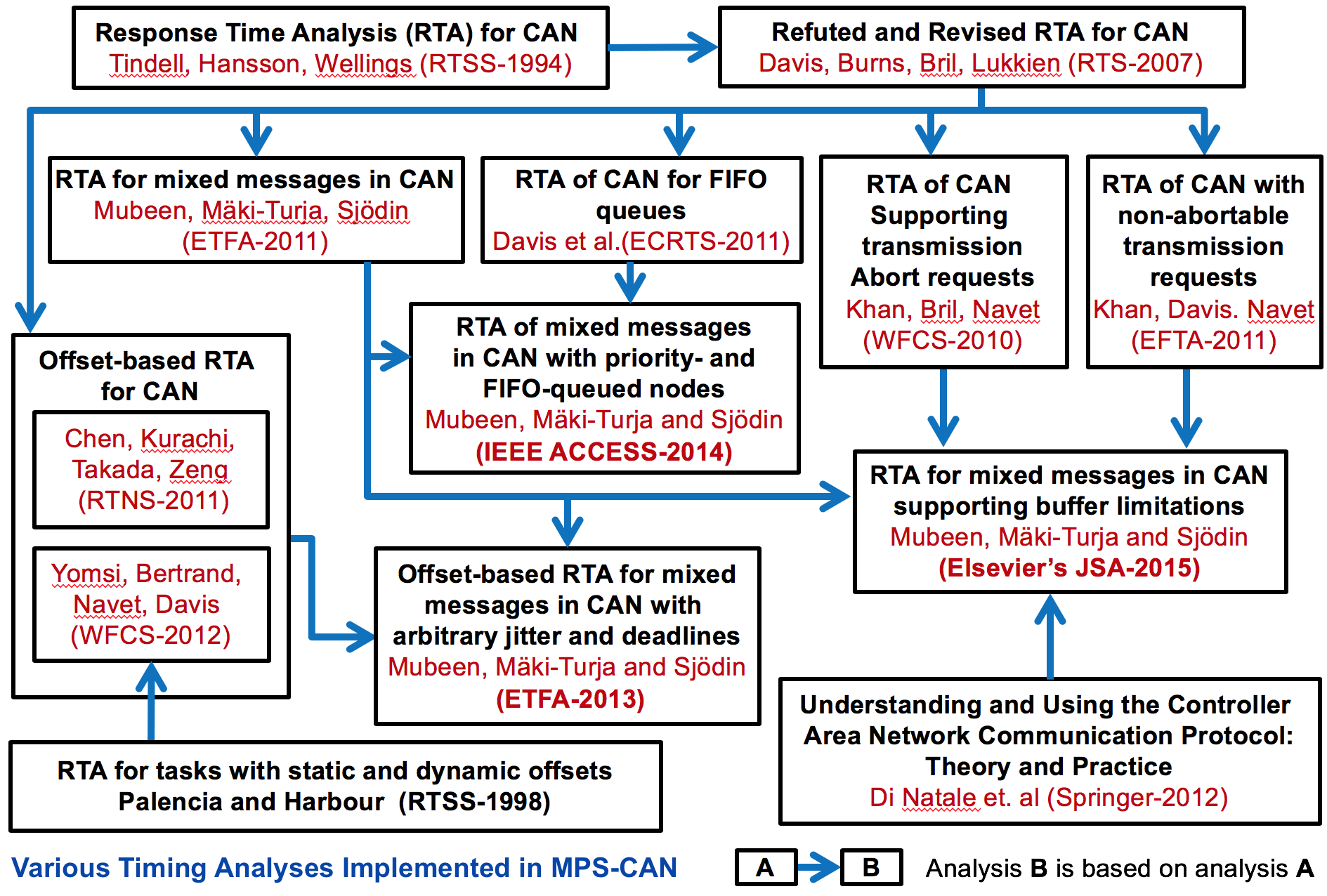
MPS-CAN Analyzer
MPS-CAN Analyzer (a freeware tool developed by us) is a response time analyzer for Mixed Periodic and Sporadic messages in Controller Area Network (CAN). It implements a number of response-time analyses for CAN addressing various queueing policies, buffer limitations in the CAN controllers, and various transmission modes implemented by higher-level protocols for CAN. It also integrates the response-time analysis for Ethernet AVB and CAN-to-Ethernet AVB Gateway.
Rubus-ICE
A commercial tool suite developed by Arcticus Systems and used in the vehicle industry to which we have contributed.
Rubus ICE (Integrated Component Model Development Environment which we have contributed to) provides an integrated environment for model-driven software development of applications ranging from small time-critical embedded systems to very large mixed time-critical and non-time critical embedded systems.
MECHAniSer
A freeware tool suite developed by Matthias Becker to support design and analysis of cause-effect chains in automotive systems.