Active Projects
FASTER-ΑΙ: Fully Autonomous Safety- and Time-critical Embedded Realization of Artificial Intelligence
FASTER AI addresses emergent needs to embed machine learning (ML) inference capabilities within hardware infrastructure of critical importance and use. We focus on hardware utilized widely in telecommunications as well as airborne systems and other vehicles. Current ML workflow programming tools are controlled primarily by dominant cloud vendors and overlook non-commodity use, focusing solely on standard AI accelerators. However, as ML inference takes over traditional heuristic- and control-based decision-making in the industry there are major needs to re-purpose that hardware towards the use of ML. Driven by use cases of safety- and time-critical functions, we streamline our ML integration pipeline around three core activities: 1) finding a suitable neural architecture, compressed-enough to fit the constraints of special hardware, 2) achieving multi-stage cross-compilation of critical logic and ML functions and, 3) equipping critical hardware with proper runtime support in order to actuate to data-application demands without sacrificing safety and service time guarantees. Our methodology is effective for current hardware but also future-proof for upcoming architectures or releases of special accelerators used in critical decision-making industries. We strongly believe that the FASTER AI approach is the most sustainable way forward toward digitalizing and creating value out of our existing critical infrastructures while also maintaining a relevant outlook for the future.

GreenDL:
Green Deep Learning for Edge Devices
Despite the continuous improvement of deep learning (DL) design and deployment frameworks, an energy-efficient design process guaranteeing user constraints (accuracy, latency, and energy consumption) is still missing from the energy saving perspective.
GreenDL aims to develop theoretical foundations and practical algorithms that (i) enable designing scalable and energy-efficient DL models with low energy footprint and (ii) facilitate fast deployment of complicated DL models for a diverse set of Edge devices satisfying given hardware constraints. To address research challenges, we will design the greenDL framework for energy-efficient design and deployment of DLs on Edge devices.

SafeAI:
Dependable AI in Safe Autonomous Systems
Data-driven development methods show great promise in producing accurate models for perception functions such as object detection and semantic segmentation, however, most of them lack a holistic view for being implemented in dependable systems. This project proposal aims at producing Machine Learning (ML) models of robust nature to meet and stay ahead of emerging certification requirements. A large part of the accuracy and robustness of a trained model is due to the data it was trained on, yet most research today focuses on model architecture development. It is the intention of this project to emphasize the dataset side of the problem, including novel methods of data augmentation e.g. neural augmentation. The expected outputs of the project would be to set the basis of a safety-conscious ML system and provide the methodology to iterate and refine such systems.

AutoDeep:
Automatic Design of Safe, High-Performance and Compact Deep Learning Models for Autonomous Vehicles
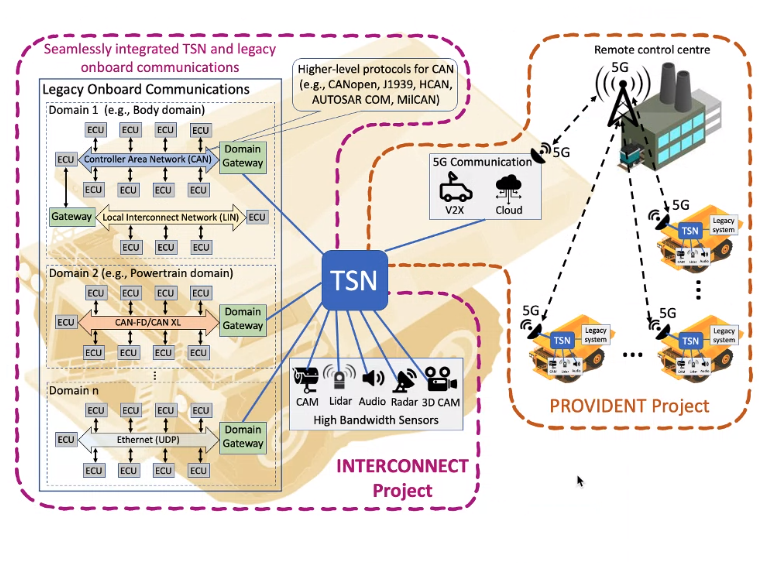
INTERCONNECT:
Integrated Time Sensitive Networking and Legacy Communications in Predictable Vehicle-platforms
PROVIDENT:
Predictable Software Development in Connected Vehicles Utilising Blended TSN-5G Networks
Finished Projects

SafeDeep:
Dependable Deep Learning for Safety-Critical Airborne Embedded Systems
This project addresses design methods for the use of DNNs in airborne safety-critical systems. DNNs cannot rely on traditional design assurance techniques described in documents from certification authorities or standardization bodies. In this project, the research focus is on mitigation techniques for design errors in both hardware and software and for adversarial effects which can lead to system failures. The expected results are design methodologies and fault tolerant architectures for airborne safety-critical applications using neural networks.
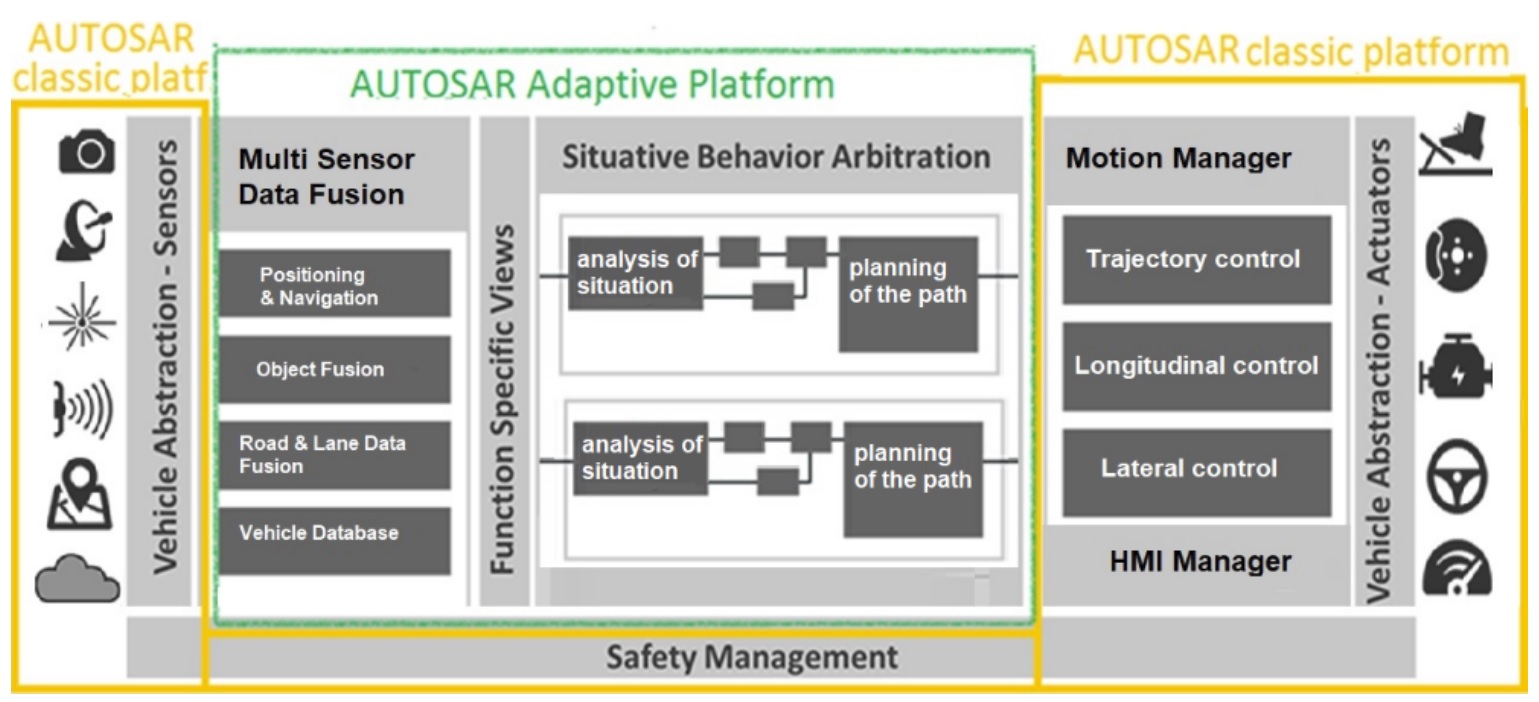
DESTINE:
Developing Predictable Vehicle Software Utilizing Time Sensitive Networking
Recent advancement in the functionality and new customer features in modern vehicles, especially autonomous vehicles, requires massive computational power and high-bandwidth on-board real-time communication. While there is a lot of research done to meet the challenge of computational requirements, relatively small efforts have been spent to deal with the challenge of supporting the high-bandwidth onboard communication requirements. In a recent effort to support high-bandwidth low-latency onboard real-time communication in modern vehicles, the IEEE Time-Sensitive Networking (TSN) task group has developed a set of standards targeting different classes of real-time traffic, support for time-triggered traffic at the same time as non-real-time traffic, support for resource reservation for different classes of traffic, support for clock synchronization, and providing several traffic shapers. However, a complete development support including modelling, timing analysis, configuration, deployment and execution for vehicular applications that use TSN is still missing from the state of the art. Since TSN is a complex technology with many options and configuration possibilities; taking full advantage of TSN in execution of complex vehicular functions is daunting task. This project aims at developing innovative techniques to provide a full-fledged development environment for vehicular applications that use TSN as the backbone for on-board communication. One unique characteristic of the project consortium is that it offers a clear value chain from academia (MDH), through the tool developer/vendor (Arcticus), and to the end user of the technology (Volvo), who will use the techniques and tools to develop prototype vehicles.
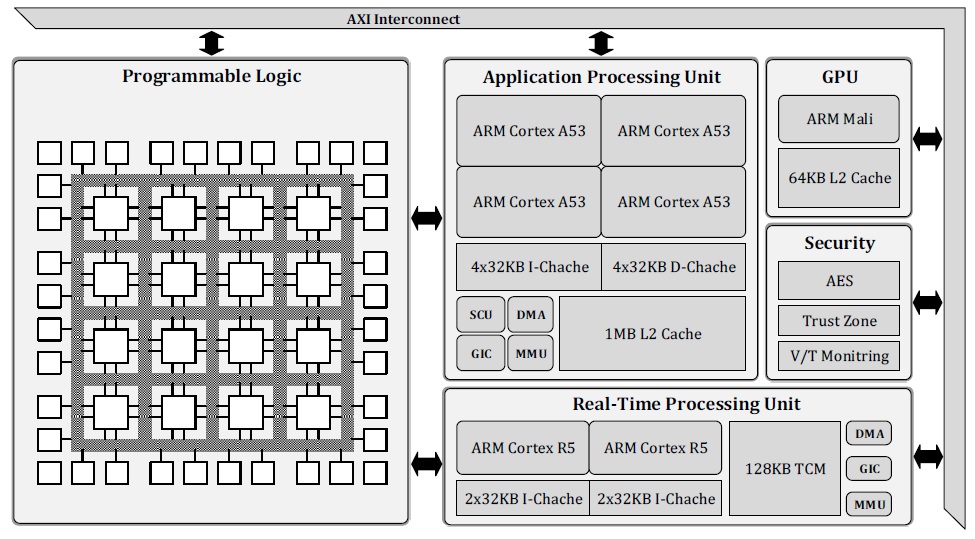
HERO:
Heterogeneous systems - software-hardware integration
The need for high-performance computing is increasing at a daunting pace and computational heterogeneity is the answer. High-performance computing platforms are increasingly becoming heterogeneous, meaning that they contain a combination of different computational units such as CPUs, GPUs, FPGAs, and AI accelerators. This computational power is needed both in hyped products like autonomous vehicles, but also in (maybe) less obvious cases like industrial automation where future intelligent production will be based on smart, autonomous, and collaborative industrial robots.
When this diverse range of computing architectures are put together on a single board (or a single chip even); the main challenge is to maximize the use of the huge computational power and at the same time to meet several criteria like performance, energy efficiency, real-time response, and dependability. To overcome these challenges, programmers of heterogeneous systems are expected to write parallel software, explicitly describe potential parallelism in their code, and identify which computations should be executed by which type of computational units. Currently, these activities are mostly manual, thereby difficult, slow, and error-prone.
The overall goal of HERO is to provide a framework that enables development of optimized parallel software, automatic mapping of software to heterogeneous hardware platforms, and provision of automatic hardware acceleration for the developed software.
Through HERO, Mälardalen University and five companies will develop deep competence to bridge the syntactic and semantic gap between modeling and programming languages, as well as automatically manipulating artifacts for analysis and synthesis of software for multiple heterogeneous targets. We will be able to drastically enhance the current practices for the design, analysis, and synthesis of parallel software for heterogeneous platforms. We will advance the knowledge on how to design and implement efficient functions for next-generation advanced hardware platforms and develop support for hardware programming, thanks to automatic synthesis of accelerators for heterogeneous parallel platforms.
HERO represents a substantial step towards an innovative solution for systematic and efficient development of complex heterogeneous systems. The research conducted in HERO is expected to provide substantial advances to the current state of the art in (i) model-based development and resource analysis of parallel software, (ii) pre-runtime code-level resource analysis, and (iii) automatic hardware acceleration.
The HERO team is composed of a strong group of researchers covering all aspects of the Synergy, with proven research records, and a group of companies strategically important for Swedish industry. Moreover, the Embedded Systems research environment at Mälardalen University represents the ideal soil for HERO, where we draw from, and contribute, to the rich and deep competence in embedded systems.
DeepMaker:
Deep Learning Accelerator on Commercial Programmable Devices
DeepMaker aims to provide a framework to generate synthesizable accelerators of Deep Neural Networks (DNNs) that can be used for different FPGA fabrics. DeepMaker enables effective use of DNN acceleration in commercially available devices that can accelerate a wide range of applications without a need of costly FPGA reconfigurations.
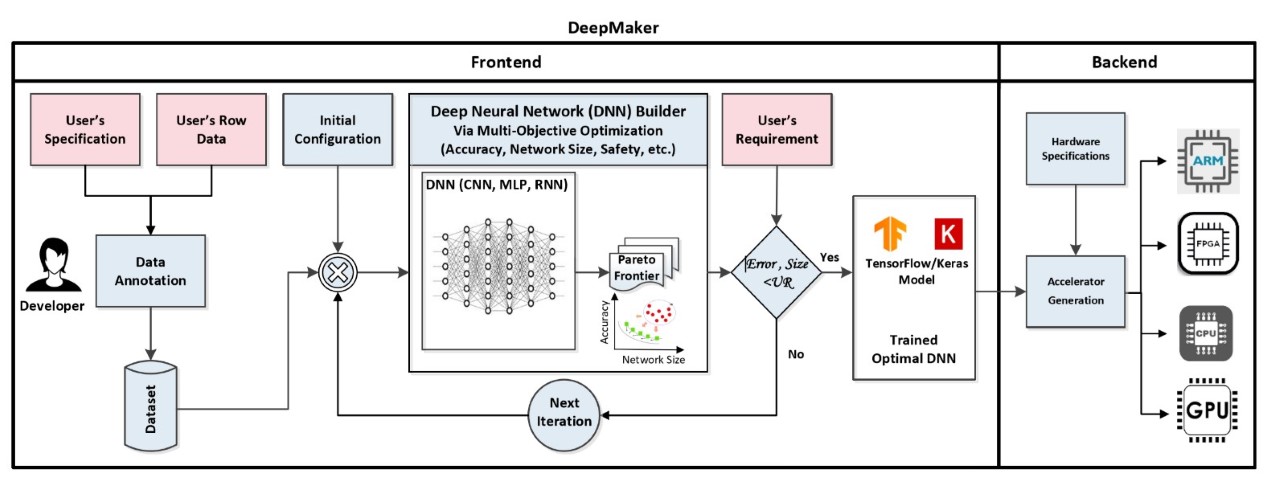
DeepLeg:
Energy-Efficient Hardware Accelerator for Embedded Deep Learning
In this joint project, we aim at decreasing the power consumption and computation load of the current image processing platform by employing the concept of computation reuse. Computation reuse suggests temporarily storing and reusing the result of a recent arithmetic operation for anticipated subsequent operations with the same operands. Our proposal is motivated by the high degree of redundancy that we observed in arithmetic operations of neural networks where we show that an approximate computation reuse can eliminate up to 94% of arithmetic operation of simple neural networks. This leads to up to 80% reduction in power consumption, which directly translates to a considerable increase in battery life time. We further presented a mechanism to make a large neural network by connecting basic units in two UT-MDH joint works.